
During performance testing of the Rails 5.0.0 release we discovered two bugs in Rails. One data corruption bug that occurs when two threads transmit on the same channel, and another bug causing socket leaks that could eventually make your server grind to a halt. We investigated and implemented fixes, one of which was promptly merged into rails; the other is still under review. This blog post is a short story on how the Phusion team (authors of the popular Passenger application server) discovered, investigated and solved these issues.
We have been tracking Rails 5 prereleases, making sure Passenger supports all the new features along the way. When the second release candidate dropped and the full release was around the corner, we decided it was a good time to look into how ActionCable fares under slow client conditions.
What are slow clients, why are they problematic?

Slow clients may cause problems in situations where a single worker is responsible for sending responses to many clients. In theory, the worker could block while waiting for the slow client to consume its response, thereby degrading the performance for all clients of that worker. The slow client could effectively DoS the application. You can read a more detailed description in an article we wrote about Raptor.
Simple test case
Hongli had skimmed through the implementation of ActionCable and suspected it might have problems dealing with slow clients. So we formulated a plan of action and I implemented a small Rails 5 application to put ActionCable to the test. Shown below is the source code of the test application that has all the stress testing logic.
class SlowClientBenchmarkChannel < ApplicationCable::Channel
LOTS_OF_DATA = "a" * 15_000
INITIALIZATION_MUTEX = Mutex.new
def subscribed
INITIALIZATION_MUTEX.synchronize do
@@clients ||= Concurrent::Hash.new
# Once per process spawn a thread that broadcasts a timestamp every second
@@time_stamp_thread ||= Looper.run(1) do
ActionCable.server.broadcast 'timestamps',
time: Time.now.to_f
end
# Once per process spawn a thread that broadcasts random data 30 times per second
@@random_data_thread ||= Looper.run(0.033) do
ActionCable.server.broadcast 'peers',
peers: @@clients.map { |c| { data: rand, more_data: LOTS_OF_DATA } }
end
end
@@clients[self] = {}
stream_from 'timestamps'
stream_from 'peers'
end
def unsubscribed
@@clients.delete(self)
end
end
When the first client joins the subscribed method should spawn two threads that send messages to subscribers at a steady interval. For every client the method subscribes that client to the two message streams.
Two kinds of messages are sent in this channel. The first contains a timestamp that is compared to the current time in the browser. This is used to approximate the time spent between sending and receiving of the message. The timestamp message is sent every second or so.
The second kind of message just contains a blob of random data and is sent many times per second. The big random data message kind will not give your regular broadband connection any trouble, but a slow client will cause the application to buffer up the blobs of random data. This is the situation we are looking for.
Discovery of a data frame corruption issue
The slow client issue did not immediately emerge however, instead there was a curious bug. As I increased the size of the LOTS_OF_DATA into the tens of thousands of bytes the websocket connection would suddenly be killed by the browser. The browser would print an error to the console citing invalid UTF-8.
A quick look into the Rails source code showed that it should not be possible for a message to have non UTF-8 content as each message is encoded in a JSON document. The Passenger team got together and fired up Wireshark to find out what exactly was sent over that WebSocket.
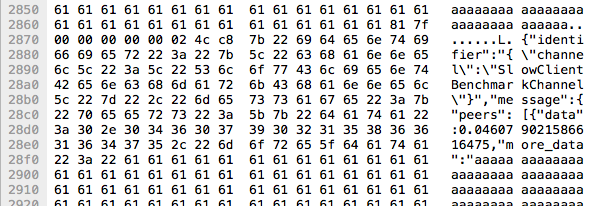
As we were peering through the captures Daniël's keen eyes spotted the corruption in one of the websocket frames. Right in the middle of one of the 'aaa..aaa' frames there is the start of a new frame. Not just its contents but also the full WebSocket frame header. The frame header contains binary data that definitely will not be valid UTF-8 which explains the browser exception message.
The method ActionCable.server.transmit builds the JSON message and then, through a series of abstractions, sends it directly into the IO socket that it has hijacked from the application server. If the messages are sent as a whole sequentially into the socket then this means the write call itself overlapped them onto the socket.
I was a little curious why this happens so I browsed through ruby/ruby's io.c to find out what IO#write does exactly, and found it is a straight up single call to write(2). This means this behaviour is dictated by the implementation of the operating system. The write(2) manpage says that POSIX specifies writes are atomic only for regular files, which does not include sockets. There's a Stack Overflow answer in which someone explains that Linux tries to do atomic writes but fails in certain circumstances, and neither OS X nor BSD guarantee anything.
With that information the solution was near at hand. To ensure that two or more transmissions never overlap their write invocation we put a lock around the call to write to the socket. We submitted a patch to the Rails Github project. The PR is currently pending review, an issue involving concurrency always warrants careful consideration.
Discovery of a socket leaking issue after refreshing
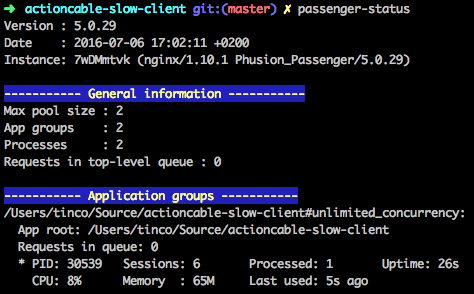
While we were working on finding out what was going on Daniël noticed something else. Even on healthy connections refreshing the page would cause the number of active sessions in Passenger to increase monotonically. Showing the amount of active sessions is something Passenger's passenger-status tool makes easy.
Rails was leaking sessions. Another dive into the ActionCable internals revealed that Rails uses the Rack hijack API to get full control over the socket. However, that also means that ActionCable becomes responsible for closing the socket when it is done, yet it does not do so. To solve this we located the method that finishes up after the connection and added a call to close the underlying hijacked socket. We made a small patch and submitted it to Rails and it was swiftly merged.
Conclusion

We have eliminated two bugs that arose when we put ActionCable under stress. We found a bug that could occur when two threads tried to transmit a large websocket message at the same time, and another that occurs when a websocket client disconnects. Subsequently, we submitted two small patches that contributed to Rails being the reliable software we expect it to be, even under extreme conditions.
With all this bug fixing we haven't yet gotten to the actual detection of a slow client problem, that's the subject for the next blog post, so if you liked this read, please stay tuned and subscribe to our blog newsletter!
 Follow on Github
Follow on Github