Help! Load spikes!
You have an application that is serving a lot of traffic. In an ideal world, your server setup is powerful enough to let your app handle any incoming user request immediately. But in the real world, sometimes there is temporarily more traffic than expected (yay!), or maybe you're affected by a third-party dependency slowdown (boo!).
In theory, you could use a queue to provide a better experience to your users. Instead of immediately sending an error that their request couldn’t be handled, you queue the request and promise to handle it as soon as possible, first come first serve.

But there's a catch! As much as users don't like having their requests rejected without being served, they also hate standing in line if it takes too long. How can you make sure that there's a great balance between getting served and not waiting too long with the queue mechanism?
Sizing up the queue helps.. sort of
One way to prevent queue lines from getting too long is by limiting the queue size. This is a good idea regardless of any traffic spikes, since each queued request takes up a bit of memory for header and accounting storage, and servers don't have unlimited resources.
But to what size should we limit the queue then? Too short and it won't be able to cover load spikes without starting to give out errors. But the bigger we make the queue, the more time the app will need to work through queued requests to fully recover from the load spike. And while that is still in progress, all new requests will have to get in line and wait, making for a degraded experience for everyone.
Even worse, longer queue times will cause users to reload (generating duplicate requests to our app), and while they are queued they'll also see their browser loading icon with no feedback as to what's going on. With just a queue size limiter, it's hard to predict much about the duration of delays in a rush hour situation.
For example, an app that can handle 2000 Requests Per Minute (RPM) will happily munch through a queue size of 100 requests in a matter of seconds, but that time will be significantly longer if the app is only able to do 200 RPM. And what an app can handle may also vary from minute to minute.
While we can probably figure out a queue size that the server can deal with in terms of memory storage, it doesn't give us more than some ballpark control over the expected delays, so we're going to need something more if we want fine-grained control over our user experience during extreme conditions.
Optimizing for user experience
It's actually queue time, rather than queue length, that matters the most for user experience. So what if we could control how long users stand in line in our queue? For example, suppose we only handle requests that have been waiting for 5 seconds and skip over anything older?
This way, we would make sure we keep servicing user requests during heavy load as long as the time spent in the queue seems reasonable, and if not, we can return a friendly error page (rather than an indeterminately spinning loader).
A user that is rejected does lose their place in the queue so it's not as fair as allowing for longer queues, but on the other hand, they do get much more deterministic feedback: the response time is either reasonable, or they know to back off a little. Skipping over old requests also allows the app to recover much faster and return to normal service.
Letting Passenger do the work
As an application server, Passenger sits in the middle of the request stream and already has queueing functionality built in. We've recently added the max_request_queue_time feature to Passenger Enterprise 5.1.12, so that implementing friendly queueing is a matter of simply tuning two options. Here's how it works:
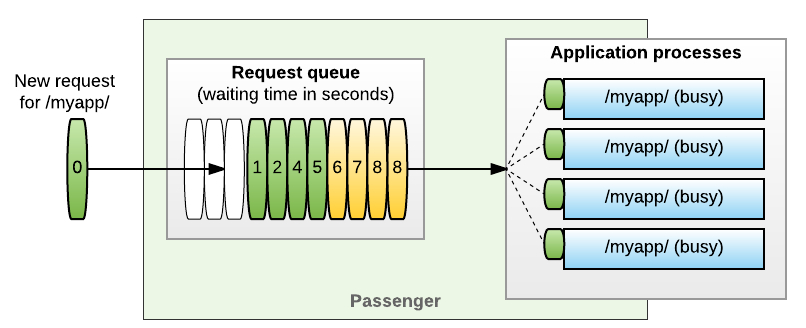
When all application processes are busy, Passenger stores new requests in a queue and the entry time is marked for each to track their individual waiting time. For example, in the diagram above, the two requests on the right both came in 8 seconds ago. The maximum size of the queue is set to 11 in this example, but Passenger has highly optimized request storage, so we don't have to worry about much larger queue sizes. A reasonable maximum to start with could for example be twice the amount of requests your app can normally handle per minute.
Whenever one of the application processes is ready for a new request, the queue is first scanned for requests that have become too old. In our example we've set the maximum queue time to 5 seconds, so the four requests that are too old (yellow) will be dropped from the queue with an error response.
It is likely that the user behind any dropped request has already given up or pressed reload anyway, which is why we skip them to service the younger requests faster and keep those users happy. In fact, some services will even automatically abort requests that take too long, such as Heroku (30 seconds).
Summary
Queues are a great way to improve the service of your application for users during busy times: instead of returning a bunch of errors right away, you can queue requests and buy a little time for your application to work on them.
The problem with queues is that they shouldn't be too short, because they will overflow during a sudden flood (and return errors), but also not too long, because user experience degrades with waiting time. An additional issue is that it's hard to say anything about waiting time by only controlling the size of the queue, because the processing time of queued requests is not a fixed number.
You can optimize the user experience during rush hour by limiting the time a request may spend in the queue. We've introduced a new option in Passenger Enterprise to make it easy to use this mechanism: max_request_queue_time. Together with the existing max_request_queue_size option, you can tune your app to gracefully handle load spikes; keeping up the service even if requests are overflowing its capacity (using queue size), while at the same time keeping it responsive via an intuitive metric (using waiting time).
 Follow on Github
Follow on Github