
Procrastination can get you into a lot of trouble, work just builds up until you have to spend all your time just catching up. It’s the same with web apps, if you just defer work until after sending the response you’ll still run into scaling problems. The only real solution is to delegate (to a worker system), not to defer, as we’ll see below.
The topic that I will be exploring today is how different app servers handle apps that defer work (such as resizing an uploaded profile picture, or removing temporary files generated during the request) out of the standard request-response cycle until after the complete response has been written back, and problems associated with different approaches.
The Restaurant Analogy: Serving Clients with Your Web App
Imagine your server is like a restaurant:
- Customers (your users) place orders (make requests).
- Waiters (the app server or web server) relay the orders.
- The cook (web app) prepares the food (response).
- The waiters deliver the finished dishes.
In this scenario, neither the cook nor the customers have to think about what the other is doing.
The waiter's job in a small restaurant is fairly straightforward. They take an order, relay it to the cook, and when the food is ready bring it to the customer. They are then free to take another order, and the process repeats. The only part of the process that requires waiting on the part of the customer is the preparation of the food.

Scaling Up
Now imagine a bigger restaurant with multiple cooks who all work on independent stations, and can all handle orders. The waiter can take multiple orders at once and provide each cook with one each, so that the wait time for each customer is reduced. The waiter's job is still fairly straightforward: keep a list of orders, and hand them out to cooks whenever they finish cooking a dish.
It should be noted that in this scenario no cook has a queue of orders; the waiter maintains a single queue shared by all cooks.

Deferred Work (and the problems therein)
However, imagine that a cook wants to get food out faster to the customer, and decides to introduce deferred work: postpone cleaning up until after the dish is delivered to the waiter. This results in reduced wait times for the customer, but also leads to a problem: the waiter receives the dish, assumes the cook is ready, and hands a new order to the cook. But the cook still has some cleaning to do, which penalizes the next customer's order. It would have been better to give the order to a cook that was actually free.
Now, if all cooks are busy with food preparation or cleaning, then it doesn't really matter (the cooks' optimization doesn't change the overall capacity of the restaurant), but in all other cases it's important for the waiter to know if a cook is really available, or still busy cleaning up.
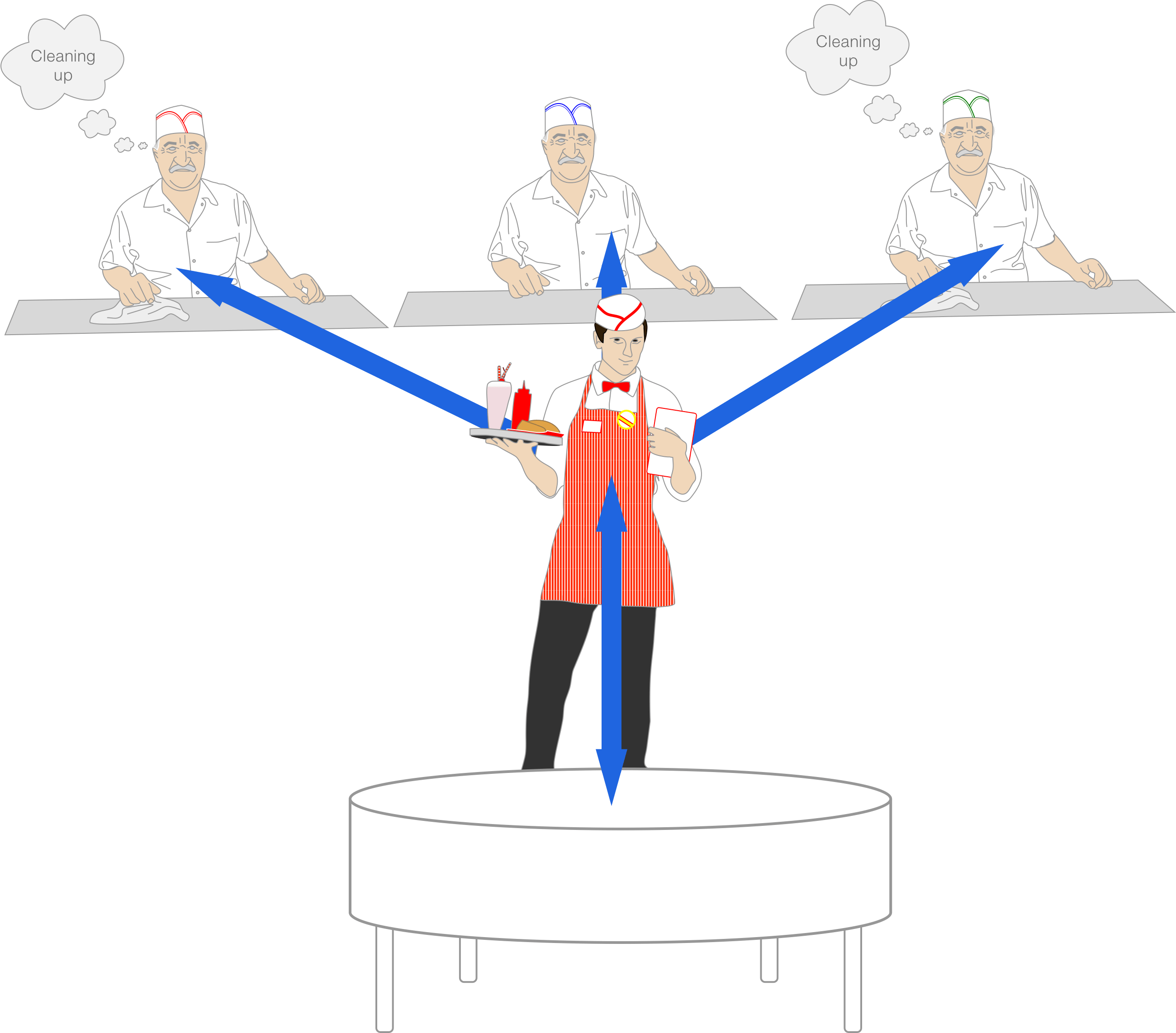
The Shared Socket Solution
One technique that some app servers use is a "shared socket". Going back to our restaurant, this would be analogous to a ticket station: the waiter inputs the orders into the ticket station, and cooks take orders out whenever they're totally free.
This technique is used by, for example, Puma and Unicorn; and it just-works™ in a standalone server (localhost) setup. For example:
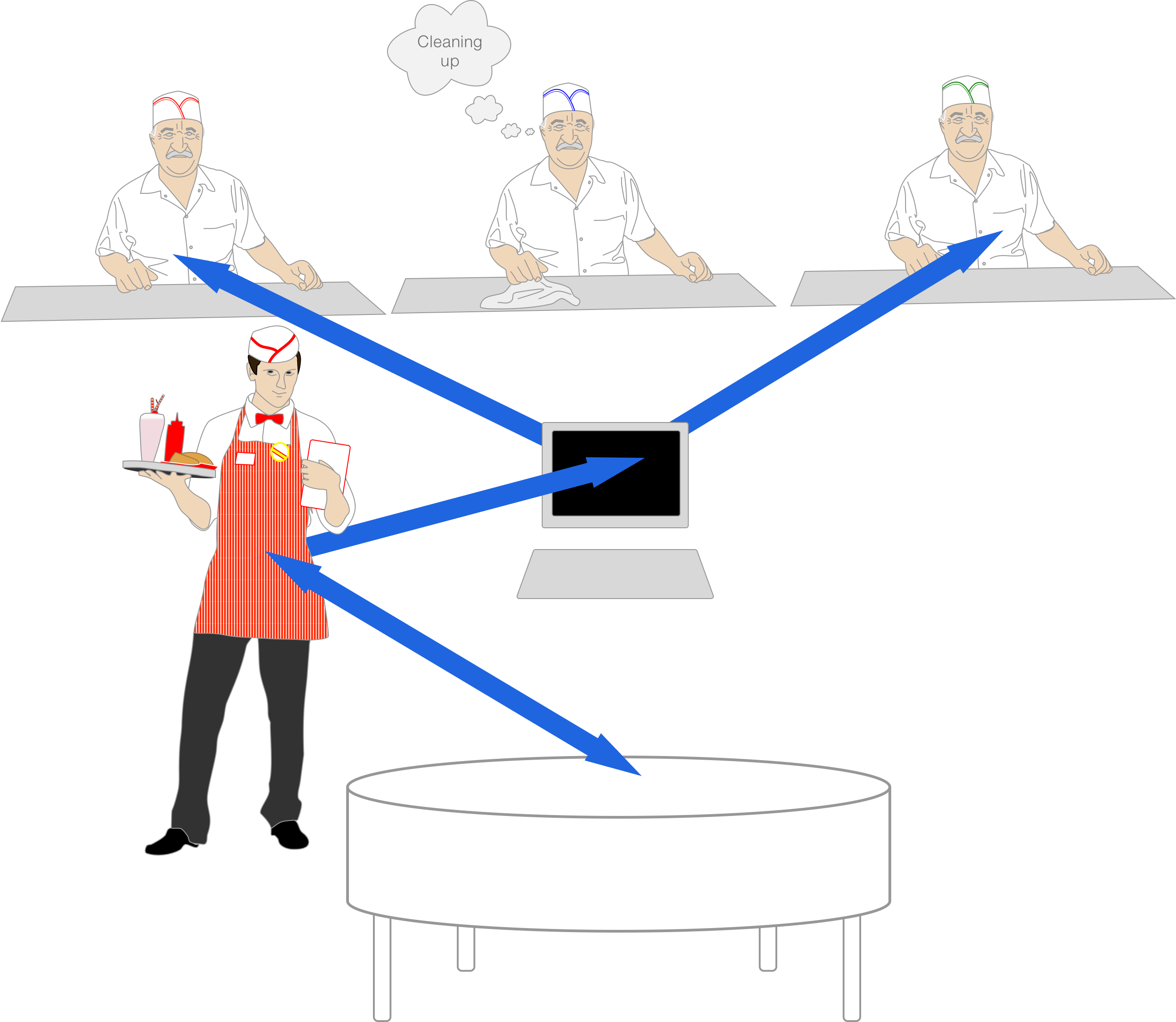
It's common practice (and highly recommended) to run a battle-tested web server in front of an app server. Suppose we picked Nginx for that purpose, and run an app server behind it that uses the shared socket technique.
In this example, all web app processes/threads (the cooks) listen on the same socket (ticket station) for a request using accept(). Therefore, Nginx (the waiter) has exactly 1 reverse proxy endpoint to connect to (again, the ticket station). Whenever Nginx connect()s, the kernel gives the connection (order) to whichever Puma/Unicorn process/thread that first accept()s. This means that for this use case, if a process/thread performs work after it has written its response but before it has completely #closed the socket, then any newly received requests will be dealt with by a different process/thread until such time as the particular app server process/thread's #close has ended, at which point it will then accept() on the socket again.
The Catch
Although this works on a single server, it limits your scaling options in the long term to scaling vertically (to a bigger machine) rather than horizontally (adding more machines), because the single socket trick doesn't work with more than one machine.
Things Fall Apart
Let's suppose that you have two app server machines with one load-balancer such as Nginx in front. Two machines cannot share a single socket, so Nginx needs to maintain two reverse proxy endpoints (two ticket machines). At that point, Nginx will either have to use round robin, or an algorithm similar to Passenger to keep track of which server has the lowest number of requests in order to decide where to send new requests. However, because the only information Nginx gets back from the app server is whether the response has been fully written, not whether the #close method has finished, it may send a request to one machine on which all threads/processes are still busy running the extra work, while the other machine is ready. This is the same problem that exists in Passenger (see below).
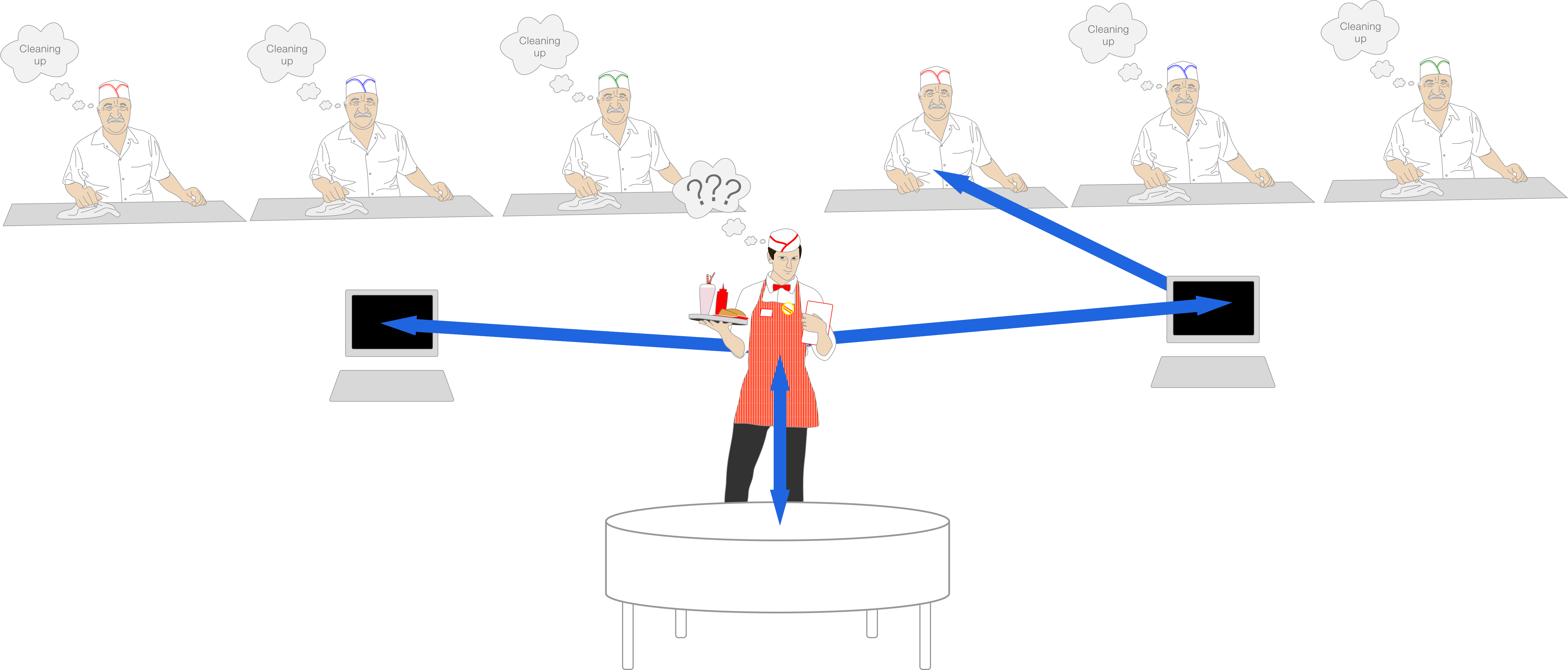
Doing deferred work after writing your response but before closing the socket is unscalable and problematic, even on a single machine. Moving the work after the response has been written, reduces the latency of single requests, but the total time before a thread/process is available to accept another request is not reduced (like the cooks who cleaned their stations while preparing food), so throughput is not any better than doing the work in the normal request lifetime. If all threads are busy doing work, then Nginx cannot forward the request to any thread, and the kernel socket queue then fills up, eventually resulting in 502 gateway errors when the queue overflows. And as we mentioned before, because this approach is limited to scaling vertically, it becomes expensive, as in most cases scaling vertically costs more than scaling horizontally (and at some point it becomes impossible to scale further vertically, ex. at Google/Amazon scale).
What Does Passenger Do?
Passenger doesn't use a shared socket like the previously mentioned app servers. As it currently stands, Passenger will route another request to an app process as soon as it is done writing its response, even if work is still being done after the request was written. In the words of our restaurant analogy, the waiter gives a cook a new order as soon as they have sent out the previous one.
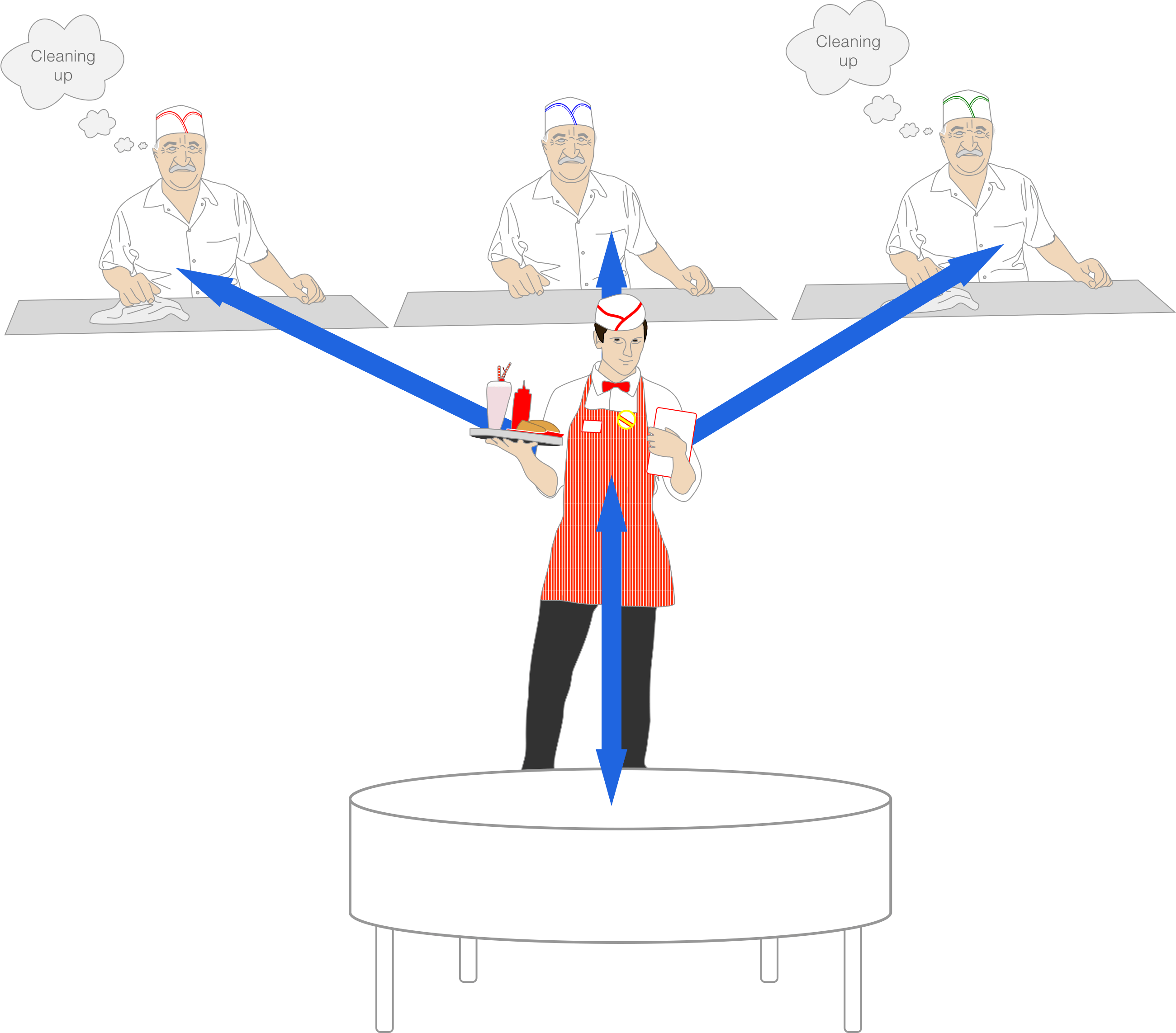
This is because the different web app processes behind Passenger do not share a single socket, they each have their own. So Passenger has to pick a specific process/thread to route to, and it does that by bookkeeping which processes are currently handling fewer requests than their advertised concurrency, as determined by which processes have finished writing their response.
Are You Going to Fix It?
While not impossible, it is quite expensive (both in processing time and in man-power to write) to emulate what the other app servers do. Given the multi-socket approach in Passenger, it would involve sending additional status messages over the socket connection. Instead of the Passenger core assuming that the thread is ready for another request as soon as the response is fully received (which is a safe assumption in the vast majority of web apps), the thread would have to explicitly send an 'I am ready' signal, and Passenger would have to wait for that signal which would require additional complexity to do in a non-blocking manner. While human cooks and waiters in a restaurant situation can just talk (or yell Gordon Ramsey-style) without the caveat of adding too much overhead time, the control signalling required by machines does. It might even cancel out the performance gains from moving work into the #close method because we would need to introduce at least one additional write call and potentially spin up a thread to keep track of the ready messages.
A Possible Alternative Solution
Passenger does provide a mechanism for running occasional work outside of the regular request cycle via our out-of-bounds-work feature (more below) which is well suited for certain types of deferred work, such as running the ruby garbage collector or batchable tasks with no hard deadline for being run.
TL;DR
At the end of the day, the design choice is a trade-off. When writing an app-server you have three choices: a single socket, multiple sockets with a busyness tracking algorithm, or to take a hybrid approach where you emulate a single socket over multiple actual sockets.
The approach used in Passenger allows it to maintain connection/request statistics on the Passenger level, which you can query with passenger-status. We have found this has been a valuable tool to have available. But does not lend itself to easily tracking when a process is finished doing work outside the request-response cycle. We chose not to go for a single socket approach because we want to support multiple programming languages. Instead of implementing statistics bookkeeping on the side of the app/wrapper (once in Ruby, once in Node, once in Python), we implemented it on the Passenger side in order to share work.
Puma and Unicorn do not have quite as sophisticated status querying tools as Passenger. They could theoretically implement statistics bookkeeping on their side (as opposed to the reverse proxy side, as Passenger does), but they haven't done so yet. However their approach allows them to wait for a process to finish any extra work it may need to do after a request before starting a new request, at least on a single box.
As to implementing a pseudo shared socket setup, we believe that the cost of doing so currently outweighs the benefits, both in terms of development time, and in terms of overhead added to the app server. Therefore we have maintained that if at all possible it is better to adopt a background-worker mechanism to perform the extra post-response work. By extracting work that causes performance problems to another process (or system altogether), primary website traffic will remain unaffected. We even support running occasional out-of-band-work using our oobw feature. And Rails has had very nice integration for active job since 4.2. Depending on your timing and job-loss tolerances, one of these systems will provide you with the best available solution to deferring work until after your request is finished.
 Follow on Github
Follow on Github